Biểu thức chính quy là gì?
Biểu thức chính quy trong ngôn ngữ lập trình là các chuỗi ký tự đặc biệt được dùng để mô tả một mẫu tìm kiếm. Nó cực kỳ hữu ích trong việc trích xuất thông tin từ văn bản như mã nguồn, tệp tin, log (nhật ký), bảng tính hoặc thậm chí cả tài liệu.
Trong khi sử dụng biểu thức chính quy, điều đầu tiên cần biết đó là về bản chất tất cả mọi thứ đều là ký tự, và chúng ta cần viết các mẫu để khớp với một tập những ký tự đặc biệt hay còn gọi là chuỗi. Ascii hoặc ký tự latinh là những ký tự nằm trên bàn phím của bạn, Unicode được sử dụng để khớp với các văn bản nước ngoài. Nó bao gồm các chữ số, dấu chấm câu và tất cả các ký tự đặc biệt như $ # @!%, …
Trong bài này, chúng ta sẽ tìm hiểu về
-
Cú pháp của biểu thức chính quy
-
Ví dụ về biểu thức w+ và ^
-
Ví dụ về biểu thức s trong hàm re.split
-
Sử dụng các phương thức biểu thức chính quy
-
Sử dụng re.match ()
-
Tìm mẫu trong văn bản (re.search())
-
Sử dụng re.findall cho văn bản
-
Cờ trong Python
-
Ví dụ về cờ re.M hoặc cờ multiline
Ví dụ, một biểu thức chính quy có thể yêu cầu chương trình tìm kiếm một đoạn chữ cụ thể từ chuỗi sau đó in nó ra kết quả tương ứng. Một biểu thức có thể bao gồm:
-
Tìm kiếm văn bản
-
Tìm kiếm lặp
-
Phân nhánh
-
Các mẫu phức hợp…
Trong Python, một biểu thức chính quy được ký hiệu là RE (REs, regexes hoặc mẫu regex) được nạp thông qua mô-đun re. Python hỗ trợ biểu thức chính quy thông qua các thư viện. Trong Python biểu thức chính quy hỗ trợ nhiều ký tự khác nhau như ký tự sửa đổi (modifier), định danh (identifier) và khoảng trắng.
| Ký tự định danh | Ký tự sửa đổi | Ký tự khoảng trắng | Ký tự thoát |
| d = bất kỳ số nào (một chữ số) | d đại diện cho một chữ số. Ví dụ: d{1,5}, nó sẽ khai báo chữ số trong khoảng 1,5 như 424,444,545, v.v. | n = dòng mới | . + *? [] $ ^ () {} | |
| D = bất cứ thứ gì ngoại trừ một số (không phải là chữ số) | += khớp 1 hoặc nhiều hơn | s = khoảng trắng | |
| s = khoảng trắng (tab, dấu cách, dòng mới, v.v.) | ? = khớp 0 hoặc 1 | t = tab | |
| S = bất cứ thứ gì ngoại trừ một khoảng trắng | * = 0 hoặc nhiều hơn | e = thoát | |
| w = chữ cái (Khớp với ký tự chữ và số, bao gồm cả “_”) | $ khớp với kết thúc chuỗi | r = ký tự xuống dòng | |
| W = bất cứ thứ gì trừ các chữ cái (Khớp một ký tự không phải là chữ và số không bao gồm “_”) | ^ khớp với bắt đầu của một chuỗi | f = ký tự nạp giấy | |
| . = bất cứ thứ gì trừ chữ cái (dấu chấm) | | khớp với x hoặc y | —————– | |
| b = bất kỳ ký tự nào ngoại trừ dòng mới | [] = khoảng hoặc “có sai lệch” | —————- | |
| . | {x} = số lượng mã trước đó | —————– |
Cú pháp biểu thức chính quy
import re-
mô-đun “re” đi kèm với Python chủ yếu được sử dụng để tìm kiếm và thao tác với chuỗi
-
Cũng được sử dụng thường xuyên cho việc “Scraping” web (trích xuất lượng lớn dữ liệu từ các trang web)
Chúng ta sẽ bắt đầu tìm hiểu về biểu thức chính quy trong bài tập đơn giản sau về cách sử dụng (w+) và (^).
Ví dụ với biểu thức w + và ^
-
“^”: Biểu thức này khớp với giá trị bắt đầu của một chuỗi
-
“w+”: Biểu thức này khớp với ký tự chữ và số trong chuỗi
Chúng ta sẽ tìm hiểu một ví dụ về cách sử dụng biểu thức w+ và ^ trong mã nguồn. Chúng ta sẽ tìm hiểu hàm re.findall sau trong bài này, còn giờ chúng ta chỉ tập trung vào biểu thức w+ và ^.
Ví dụ: với chuỗi “guru99, education is fun” nếu chúng ta chạy chương trình với w+ và ^, nó sẽ trả về kết quả “guru99”.
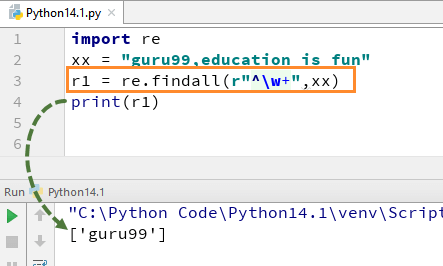
import re
xx = "guru99,education is fun"
r1 = re.findall(r"^w+",xx)
print(r1)Hãy nhớ rằng, nếu bạn xóa dấu + khỏi w+, kết quả sẽ thay đổi và nó sẽ chỉ đưa ra ký tự đầu tiên của từ đầu tiên, tức là [g].
Ví dụ về biểu thức s trong hàm re.split
-
“s”: Biểu thức này được sử dụng để tạo khoảng trắng trong chuỗi
Để hiểu cách biểu thức chính quy này hoạt động trong Python, chúng ta bắt đầu với một ví dụ đơn giản về hàm split. Trong ví dụ này, chúng ta sẽ phân tách từng từ bằng cách sử dụng hàm “re.split” và đồng thời chúng ta cũng sử dụng biểu thức s để tách mỗi từ thành một chuỗi riêng biệt.
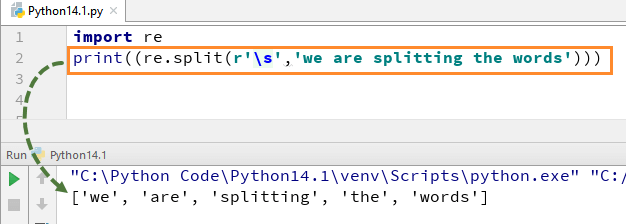
Khi bạn chạy đoạn mã trên, kết quả trả về sẽ là [‘we’, ‘are’, ‘splitting’, ‘the’, ‘words’].
Bây giờ, hãy xem điều gì xảy ra nếu bạn xóa “” khỏi s. Sẽ không có chữ cái ‘s’ trong đầu ra, điều này là do chúng ta đã xóa ” khỏi chuỗi và chương trình sẽ hiểu “s” là một ký tự thông thường và do đó nó sẽ tách các từ ở bất cứ nơi nào nó tìm thấy “s” trong chuỗi.
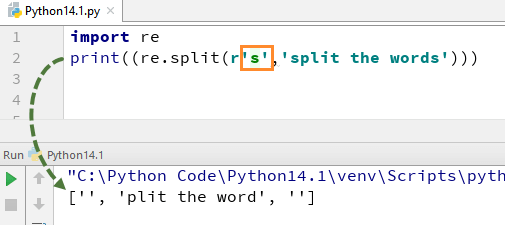
Tương tự, có một loạt các biểu thức chính quy khác trong Python mà bạn có thể sử dụng theo nhiều cách khác nhau như d, D, $, ., b, v.v.
Đây là đoạn mã hoàn chỉnh
import re
xx = "guru99,education is fun"
r1 = re.findall(r"^w+", xx)
print((re.split(r's','we are splitting the words')))
print((re.split(r's','split the words')))Tiếp theo, chúng ta sẽ tìm hiểu các kiểu phương thức được sử dụng với các biểu thức chính quy.
Sử dụng các phương thức của biểu thức chính quy
Gói “re” cung cấp một số phương thức để thực hiện truy vấn trên chuỗi đầu vào. Chúng ta sẽ tìm hiểu các phương thức:
-
re.match()
-
re.search()
-
re.findall()
Lưu ý: Dựa trên các biểu thức chính quy, Python cung cấp hai thao tác nguyên thủy khác nhau. Phương thức match chỉ kiểm tra sự trùng khớp ở đầu chuỗi trong khi đó, phương thức search kiểm tra sự trùng khớp ở bất kỳ đâu trong chuỗi.
Sử dụng re.match()
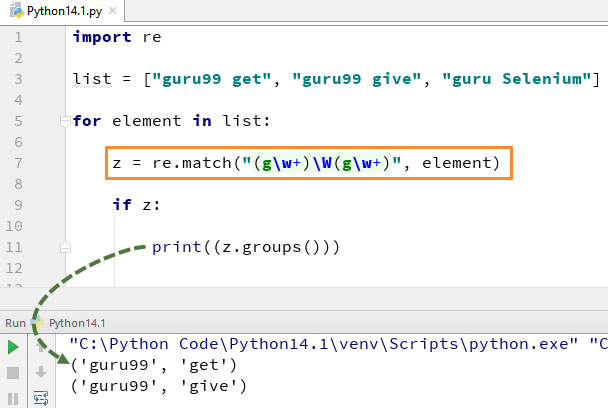
Hàm match được sử dụng để khớp mẫu RE với chuỗi với các cờ tùy chọn. Trong phương thức này, biểu thức “w+” và “W” sẽ khớp với các từ bắt đầu bằng chữ ‘g’ và sau đó, bất kỳ thứ gì không được bắt đầu bằng ‘g’ đều không được xác định. Để kiểm tra sự trùng khớp cho từng thành phần trong danh sách hoặc chuỗi, chúng ta sử dụng vòng lặp for.
Tìm mẫu trong văn bản (re.search())
Một biểu thức chính quy thường được sử dụng để tìm kiếm một mẫu trong văn bản. Phương thức này có đầu vào là một mẫu biểu thức chính quy và một chuỗi, sau đó nó sẽ tìm kiếm sự xuất hiện của mẫu này trong chuỗi.
Để sử dụng hàm search (), bạn cần nạp mô-đun re (import re) trước rồi mới thực thi mã. Hàm search() lấy “pattern – mẫu” và “text – văn bản” để quét từ chuỗi chính của chúng ta và trả về đối tượng khớp với mẫu cho trước (found a match) nếu tìm thấy hoặc trả về đối tượng không khớp (no match) với mẫu nếu không tìm thấy.

Ví dụ ở đây, chúng ta tìm hai chuỗi “Software testing” và “guru99”, trong chuỗi văn bản “Software testing is fun”. Đối với “Software testing”, chúng ta tìm thấy kết quả khớp do đó nó trả về đầu ra là “found a match”, trong khi đối với từ “guru99” chúng ta không thể tìm thấy trong chuỗi do đó nó trả về đầu ra là “no match”.
Sử dụng re.findall cho văn bản
Mô-đun Re.findall () được sử dụng khi bạn muốn lặp quá trình tìm kiếm cho toàn bộ các dòng trong tệp, nó sẽ trả về một danh sách tất cả các kết quả khớp chỉ với một bước. Ví dụ: ở đây chúng ta có một danh sách các địa chỉ email và chúng ta muốn tất cả các địa chỉ email được lấy ra khỏi danh sách, chúng ta sử dụng phương thức re.findall. Nó sẽ tìm thấy tất cả các địa chỉ e-mail từ danh sách.

Đây là đoạn mã hoàn chỉnh
import re
list = ["guru99 get", "guru99 give", "guru Selenium"]
for element in list:
z = re.match("(gw+)W(gw+)", element)
if z:
print((z.groups()))
patterns = ['software testing', 'guru99']
text = 'software testing is fun?'
for pattern in patterns:
print('Looking for "%s" in "%s" ->' % (pattern, text), end=' ')
if re.search(pattern, text):
print('found a match!')
else:
print('no match')
abc = '[email protected], [email protected], [email protected]'
emails = re.findall(r'[w.-]+@[w.-]+', abc)
for email in emails:
print(email)Cờ trong Python
Nhiều phương thức chính quy và các hàm chính quy có sử dụng một biến tùy chọn được gọi là cờ. Cờ này sẽ thay đổi ý nghĩa của mẫu biểu thức đã cho. Để hiểu thêm chúng ta cùng xem một vài ví dụ về các cờ này.
Các cờ khác nhau được sử dụng trong Python bao gồm
| Cú pháp sử dụng cờ Regex | Công dụng của cờ |
| [re.M] | Xem xét bắt đầu/kết thúc trên từng dòng |
| [re.I] | Chữ hoa hoặc chữ thường được coi như giống nhau |
| [re.S] | Tạo ra [.] |
| [re.U] | Khiến {w, W, b, B} tuân theo quy tắc Unicode |
| [re.L] | Khiến {w, W, b, B} tuân theo ngôn ngữ sử dụng trong máy. |
| [re.X] | Cho phép chú thích trong Regex |
Ví dụ về cờ re.M hoặc cờ Multiline
Trong mẫu biểu thức multiline, ký tự mẫu [^] khớp với ký tự đầu tiên của chuỗi và đầu của mỗi dòng (ngay sau ký tự dòng mới). Trong khi biểu thức “w” nhỏ được sử dụng để đánh dấu khoảng trắng bằng ký tự. Khi bạn chạy mã, biến đầu tiên “k1” chỉ in ra ký tự ‘g’ cho từ guru99, trong khi nếu bạn thêm cờ multiline, nó sẽ tìm ra các ký tự đầu tiên của tất cả các thành phần trong chuỗi.
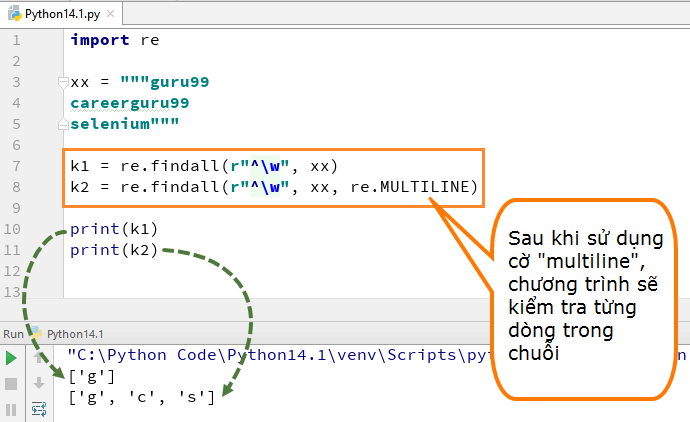
Đây là mã
import re
xx = """guru99
careerguru99
selenium"""
k1 = re.findall(r"^w", xx)
k2 = re.findall(r"^w", xx, re.MULTILINE)
print(k1)
print(k2)-
Chúng ta đã khai báo biến xx cho chuỗi ” guru99…. careerguru99….selenium”
-
Chạy mã mà không sử dụng cờ multiline, nó chỉ in ra chữ ‘g’ từ các dòng trên.
-
Chạy mã với cờ “multiline”, khi bạn in ‘k2’, nó sẽ cho đầu ra là ‘g’, ‘c’ và ‘s’
-
Qua đó ta có thể thấy sự khác biệt giữa việc có và không có cờ multiline trong ví dụ trên.
Tương tự, bạn cũng có thể sử dụng các cờ Python khác như re.U (Unicode), re.L (tuân theo ngôn ngữ sử dụng trong máy), re.X (cho phép chú thích), v.v.
Ví dụ sử dụng Python 2
Các đoạn mã trên sử dụng Python3, nếu bạn muốn chạy với Python2, hãy sử dụng đoạn mã sau:
# Example of w+ and ^ Expression
import re
xx = "guru99,education is fun"
r1 = re.findall(r"^w+",xx)
print r1
# Example of s expression in re.split function
import re
xx = "guru99,education is fun"
r1 = re.findall(r"^w+", xx)
print (re.split(r's','we are splitting the words'))
print (re.split(r's','split the words'))
# Using re.findall for text
import re
list = ["guru99 get", "guru99 give", "guru Selenium"]
for element in list:
z = re.match("(gw+)W(gw+)", element)
if z:
print(z.groups())
patterns = ['software testing', 'guru99']
text = 'software testing is fun?'
for pattern in patterns:
print 'Looking for "%s" in "%s" ->' % (pattern, text),
if re.search(pattern, text):
print 'found a match!'
else:
print 'no match'
abc = '[email protected], [email protected], [email protected]'
emails = re.findall(r'[w.-]+@[w.-]+', abc)
for email in emails:
print email
# Example of re.M or Multiline Flags
import re
xx = """guru99
careerguru99
selenium"""
k1 = re.findall(r"^w", xx)
k2 = re.findall(r"^w", xx, re.MULTILINE)
print k1
print k2Tổng kết
Biểu thức chính quy trong một ngôn ngữ lập trình là các chuỗi ký tự đặc biệt được dùng để mô tả một mẫu tìm kiếm. Nó bao gồm các chữ số và dấu chấm câu và tất cả các ký tự đặc biệt như $ # @!%, … Biểu thức có thể thực hiện những việc như:
-
Tìm kiếm văn bản
-
Tìm kiếm lặp
-
Phân nhánh
-
Các mẫu phức hợp…
Trong Python, một biểu thức chính quy được ký hiệu là RE (REs, regexes hoặc regex mẫu) được nạp thông qua mô-đun re.
-
mô-đun “re” đi kèm với Python chủ yếu được sử dụng để tìm kiếm và thao tác với chuỗi
-
Cũng được sử dụng thường xuyên cho việc “Scrapping” web (trích xuất một lượng lớn dữ liệu từ các trang web)
-
Các phương thức của biểu thức chính quy bao gồm re.match(), re.search() & re.findall()
-
Nhiều phương thức và hàm của biểu thức chính quy có sử dụng một biến tùy chọn được gọi là cờ.
-
Cờ này có thể sửa đổi ý nghĩa của mẫu Regex đã cho
-
Các cờ Python khác nhau được sử dụng trong Phương thức Regex là re.M, re.I, re.S, v.v.